SEM-in-R Basics - Estimating a PLS-SEM
Last update: July 14th, 2021
1 Video for Data Preperation for PLS-SEM
2 Tutorial in RStudio
Under construction.
3 Slide download
You can download the slides in this presentation here.
4 Slides
Here, you can find the slides from the video. Under each slide you can find the script for that slide.
Estimating a PLS-SEM (1/33)
 Hello and welcome to this Video: Estimating a PLS-SEM
Hello and welcome to this Video: Estimating a PLS-SEM
The slides in this presentation were created by: Lilian Kojan
PLS model estimation in SEMinR (2/33)

Now that you know how to specify the measurement model and the structural model in SEMinR, all that is left is model estimation. In this video, I will show you how to estimate a PLS SEM model in SEMinR. I will also talk about the model object in SEMinR and what you can do with it. Finally, I will adress some common problems that appear when you estimate a model.
Before estimation (3/33)

Before we start with estimation, let’s shortly talk about the ingredients you need to estimate a model. First, you need data as described in our video on data preparation. This data can be both in the matrix or dataframe format and must contain numerical response data. With PLS-SEM, model estimation is possible even with a small number of observations. But of course, if you have more responses, your model’s statistical power is larger. Second, you need to specify a measurement model. The measurement model is the link between your data and your structural model. A common source of trouble is a disconnect between measurement model and either the data or the structural model. For example, if the indicator names in your measurement model do not correspond with the column names in your data, or when you use a construct in your structural model that you have not defined in your measurement model. Third, in your structural model you define the relationship between the model constructs.
Before estimation - example (4/33)

For our example, we use the mobi data set which is part of the seminar package. As an example model, we use the mediation model from our structural model tutorial. For that, we define all constructs in the measurement model which we call mm. As you have learned in the measurement model tutorial, the code for all three constructs is equivalent. They each define a mode a (or correlation weights) composite construct.
Before estimation - example (5/33)

Lastly, we define the structural model which we call sm.
Before estimation - example (6/33)

Now, we are ready for model estimation. But we can also take a quick peek on how our model looks. For this, you can use the specify_model function with your measurement model and your structural model and pipe it into the plot function.
Before estimation - example (7/33)
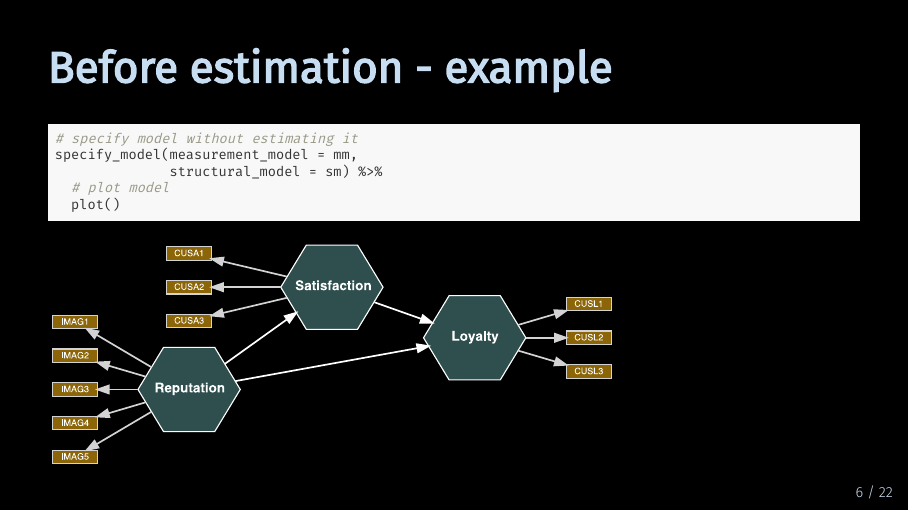
Looks about right. As you can see, by default SEMinR visualizes composite constructs as hexagons.
Estimating a model (8/33)

Now it’s time for model estimation! The estimate_pls function takes eight arguments. On a regular basis, you will likely only use these first three. Let me still quickly take you through all of them.
Estimating a model - the fundamentals (9/33)

As mentioned, these three are likely the only arguments you will need. The first argument asks for the data, the second for the measurement model and the third for the structural model.
Estimating a model - the fundamentals (10/33)

Without these three inputs, SEMinR cannot estimate your model. But these three inputs are also sufficient to estimate the model, so normally, you can just give these inputs to the estimate_pls function without specifying which argument is which. This means, that the bottom code is equivalent to to the top code.
Estimating a model - model (11/33)

Instead of providing a measurement model and structural model, you can also specify a model with the specify_model function.
Estimating a model - model (12/33)

We just used this to quickly plot our model, remember? So either you provide the measurement model and structural model directly to the estimate_pls function, or you specify the model before. By default, this argument is set to NULL.
Estimating a model - inner_weights (13/33)
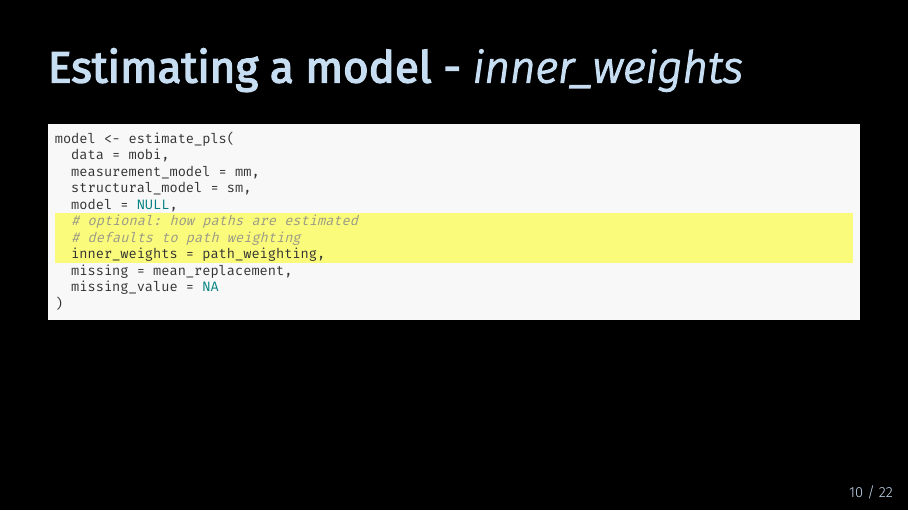
The inner_weights argument defines how paths are estimated by the algorithm. By default, this is set to path weighting which is the recommended option for most models. The other option is factor weighting.
Estimating a model - inner_weights (14/33)

When estimating a model, the results for both options will be very similar. If you are interested in the differences between these two schemes, I recommend the 2005 PLS path modeling paper by Tenenhaus et al.
Estimating a model - missing (15/33)
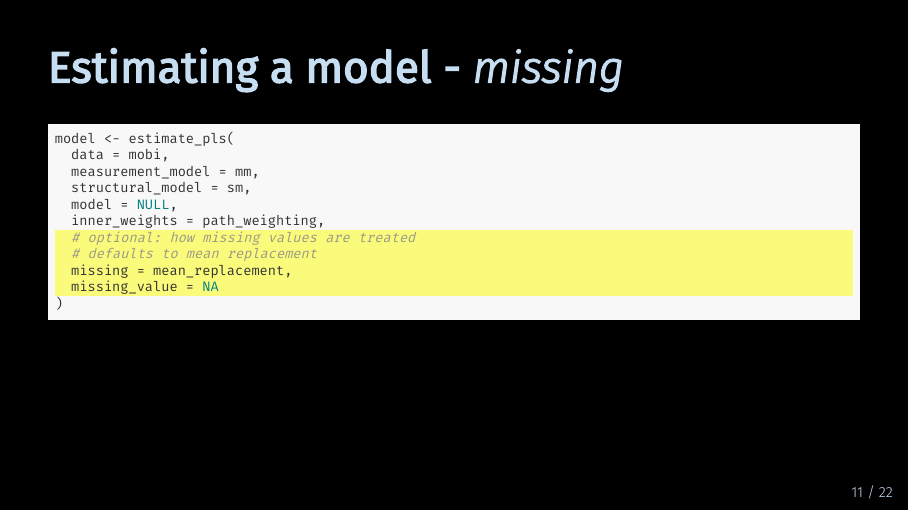
These arguments let you specify how SEMinR handles missing data. As described in our data preparation basics video, missing data means that in a variable, or column of your data set, some values are missing. By default, SEMinR uses mean replacement. That means that SEMinR replaces missing values in a column of your dataset with the mean of that column. As discussed, this might not always be the best option.
Estimating a model - missing (16/33)
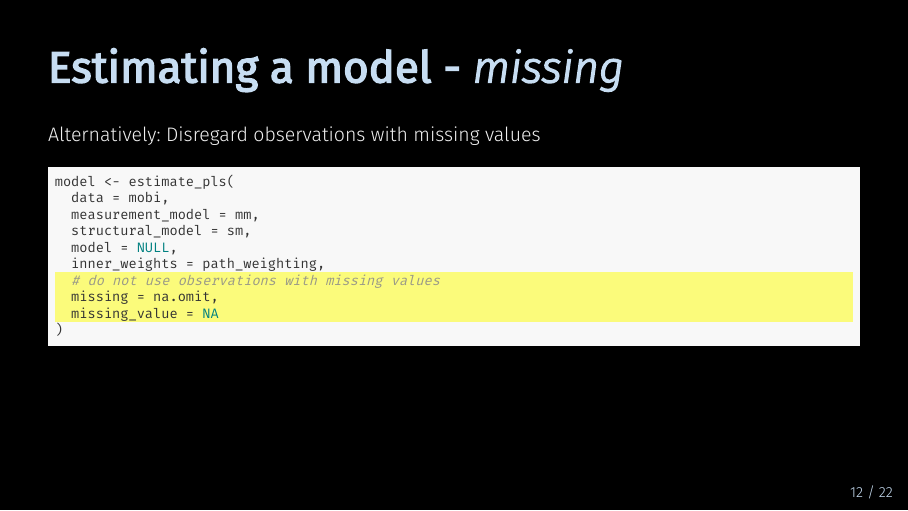
If you want SEMinR to disregard observations with missing values, choose the na.omit option. The second argument, missing_value, just tells SEMinR what missing values look like in your data. If you have formatted your data as numerical, it will be called NA anyway.
Estimating a model (17/33)

Now that we have talked through all arguments, let’s run the code. If everything goes according to plan, your code output will look like this and tell you the number of observations. If your model includes higher-order constructs or interaction terms, this will print twice because a first-stage model is estimated separately.
Now, we have a model object, what do we do with it? We have separate videos on model evaluation and bootstrapping, so let’s just take a quick peek at the model object itself.
The SEMinR model object - plot (18/33)
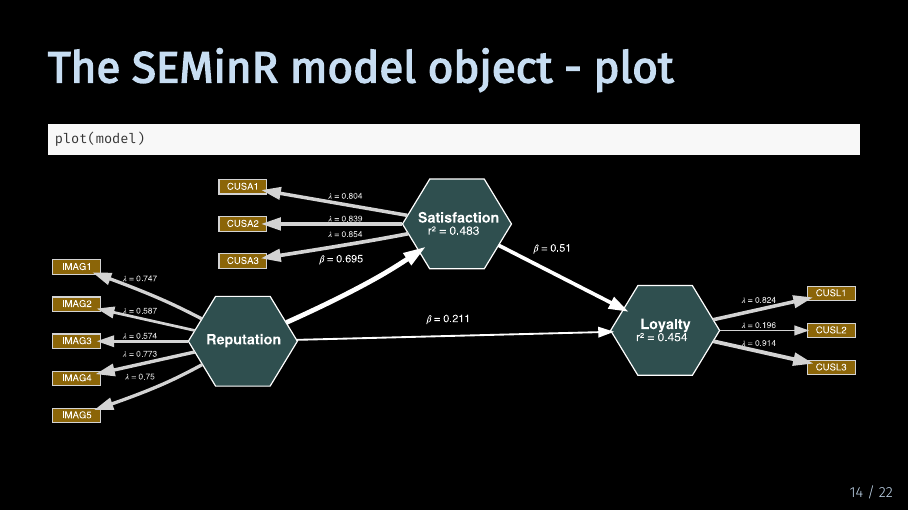 Firstly, we can of course plot it.
Firstly, we can of course plot it.
By default, the plot contains both the measurement and the structural model with path coefficients, weights and loadings as well as the explained variances R^2.
The SEMinR model object - subobjects (19/33)

If you type in model and then the dollar sign, you get an overview of the information and objects stored in the pls model object.
The SEMinR model object - subobjects (20/33)

For example, meanData contains the means of all indicators.
The SEMinR model object - subobjects (21/33)

Iterations is the number of iterations it took until the algorithm converged.
The SEMinR model object - summary (22/33)
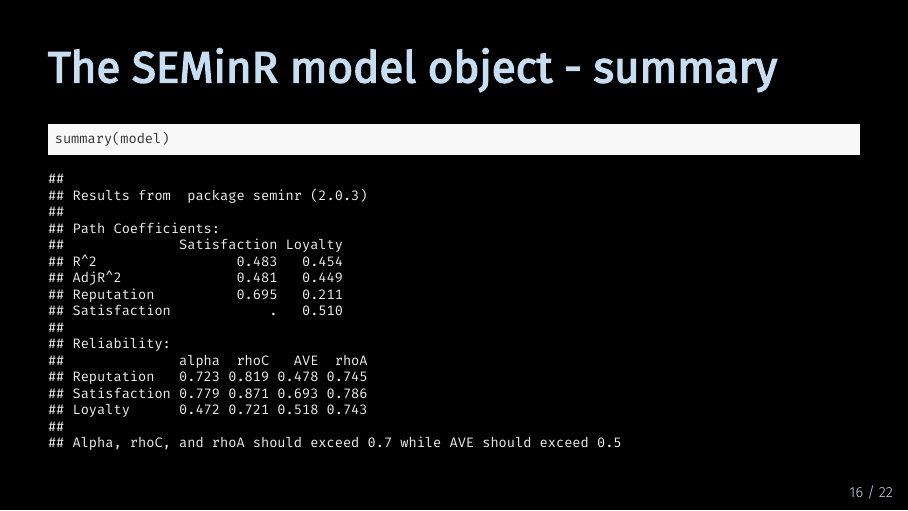
The summary function gives you a quick overview of your model results. If you just execute summary function, R prints a table with path coefficients and R^2. It also prints a table with criteria for internal consistency reliability and convergent validity.
The SEMinR model object - summary subobjects (23/33)

If you store the model summary in a separate object, you can access much more information. For example…
The SEMinR model object - summary subobjects (24/33)

You can access discriminant validity criteria like the variance inflation factor
Troubleshooting - ‘x’ must be numeric (25/33)
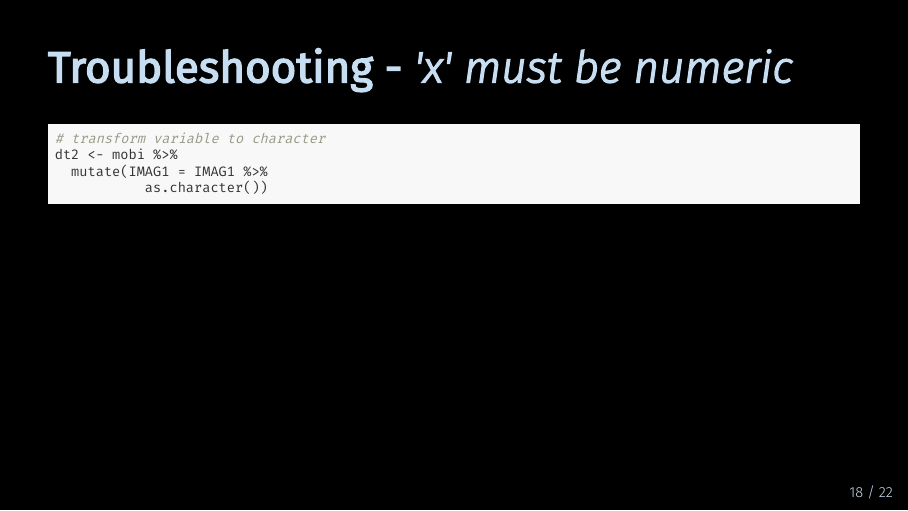 Finally, let’s look at three common problems that can happen when estimating a model. First, let’s assume our data is not numerical. For that, I make a new data set with one of our indicators formatted as a character. What happens if I try to estimate our model with that data?
Finally, let’s look at three common problems that can happen when estimating a model. First, let’s assume our data is not numerical. For that, I make a new data set with one of our indicators formatted as a character. What happens if I try to estimate our model with that data?
Troubleshooting - ‘x’ must be numeric (26/33)
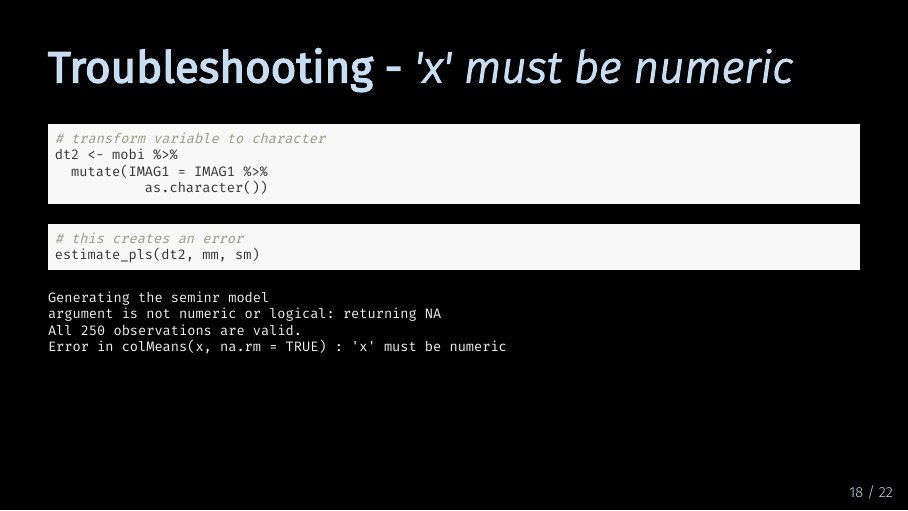
I get an error that looks something like that, telling me that my data is not numeric. So if you get an error that looks like this, you need to go back and reexamine your data.
Troubleshooting - ‘x’ must be numeric (27/33)

For example, you can select all the columns that are not numeric using the select function, the where function negated with a ! operator and the is.numeric function.
Troubleshooting - undefined columns selected (28/33)

Second, what happens if I try to access a column that is not in my data? Especially with large measurement models, typos are prone to happen. So if I mistype the Image suffix to I-M-G-A and try to estimate the model…
Troubleshooting - undefined columns selected (29/33)

The resulting error tells me that R could not find the columns I tried to select in my data. Unfortunately, I have not yet found a shortcut to correct this. As far as I know, you have to scrutinize every line of your measurement model and compare it with the column names in your data.
Troubleshooting - attempt to apply non-function (30/33)

The last common error happens when I try to include a construct in my structural model that I have not defined in my measurement model. Let’s assume I want to include a construct called quality. If I just put it into my structural model without defining how it should be measured…
Troubleshooting - attempt to apply non-function (31/33)
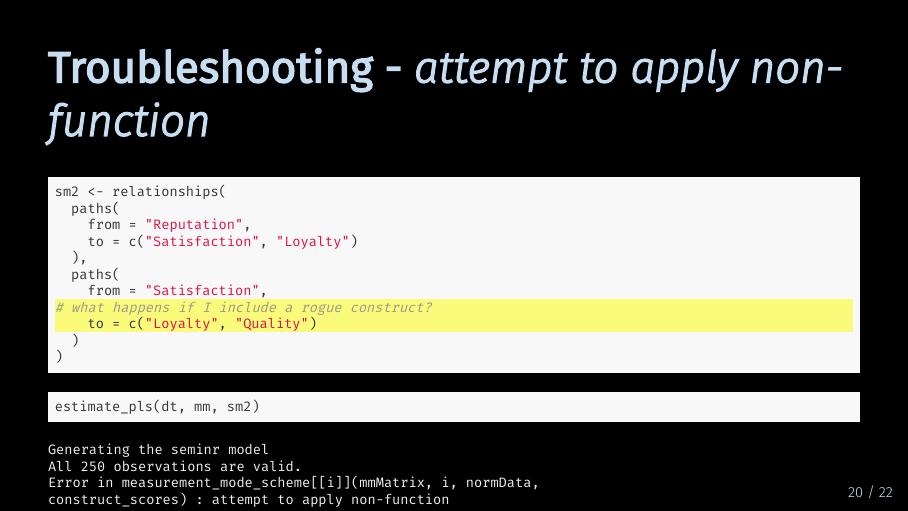
… the error message will tell me that I attempted to apply a non-function. Again, there is not really a quick way to find the culprit construct. But if you get an error message like this, you now know where to start looking: Which construct in your structural model is not defined in your measurement model?
Summary (32/33)

To finish off, let me review the contents of this video. You now know how to estimate a PLS model in SEMinR. You also know how to examine the model you have estimated. And you are familiar with common errors that can happen when you estimate a model. Now you’re ready to move on to model evaluation!
Sources for this video (33/33)

5 Next
Next up is bootstrapping your model.